概述
1.输入输出的发展
- 早期
- 分散连接
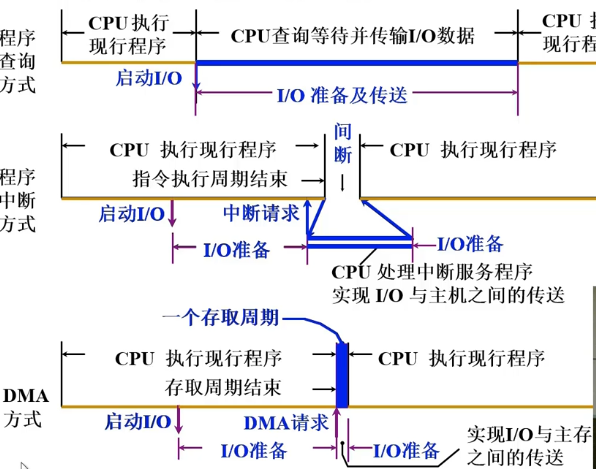
- CPU和I/O设备串行工作,程序查询方式。
- 接口模块和DMA阶段
- 总线连接
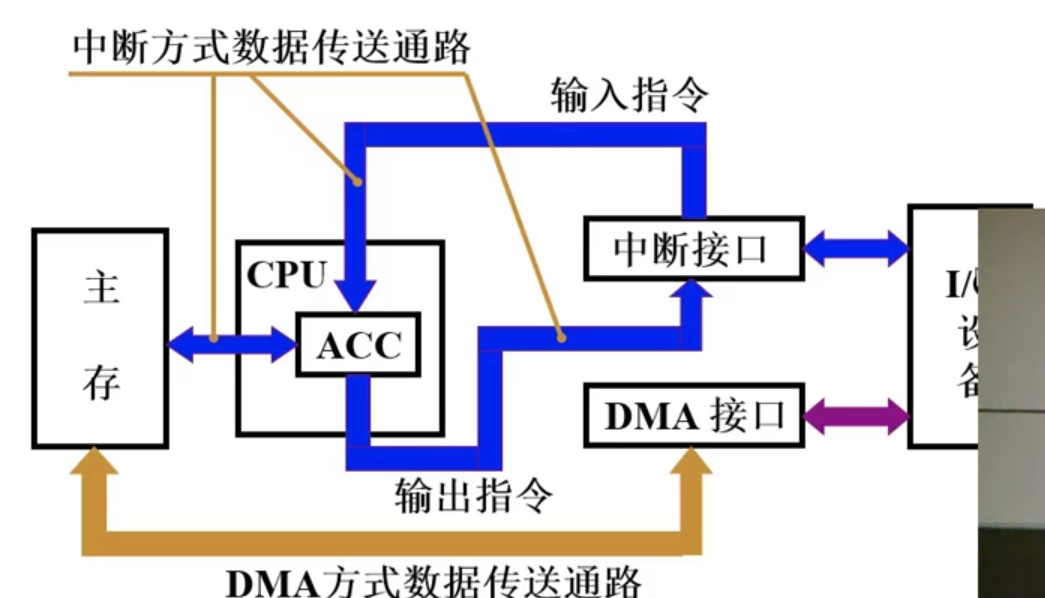
- CPU和I/O设备并行工作。1.中断方式。2.DMA方式
- 具有通道结构的阶段
- 具有I/O处理机阶段
I/O逐渐从CPU中独立出来
2.输入输出系统组成
1.I/O软件
- I/O指令 CPU指令的一部分
操作码:标识I/O指令
命令码:相当于普通指令的操作码
设备码:I/O设备编码(地址)
| 操作码 | 命令码 | 设备码 |
|---|---|---|
- 设备通过I/O接口连接在总线上和主机完成信息交换
通道方式:
- 设备连接设备控制器连接子通道连接通道
3.I/O设备和主机的联系方式
联系->得知I/O设备的地址->编址1.I/O设备的编址方式
1. 统一编址
用取数,存数指令2.不统一编址
有专门的I/O指令2.设备选址
用设备选择电路识别是否被选中3.传送方式
串行、并行4.联络方式
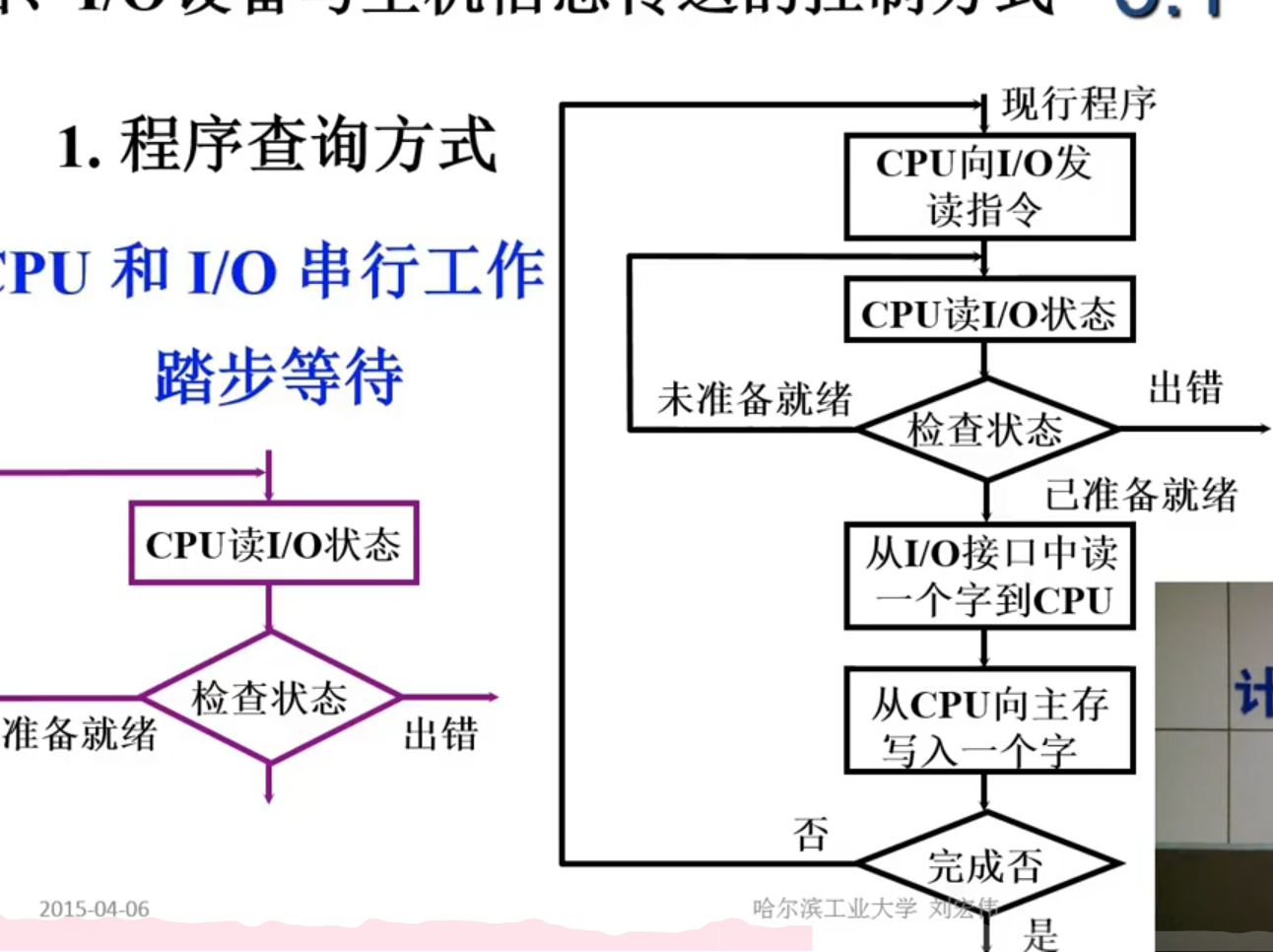
- 程序查询方式
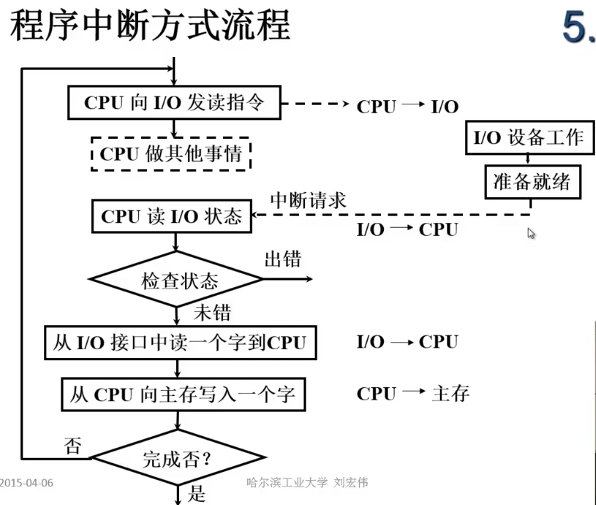
- 程序中断方式
- I/O设备准备数据时,CPU不进行查询
- I/O设备与主机进行信息交换时,CPU暂停现行程序
- 没有踏步现象,中断现行程序
- CPU和I/O部分并行工作
概述
主机<->I/O接口<->(外部设备)设备控制器<->光、电、磁部分(外部设备)
- 外部设备
- 人机交互设备
- 计算机信息存储设备
- 机-机之间通信设备
- 输入设备
- 键盘
- 编码键盘法
- 鼠标
- 触摸屏
- 键盘
- 输出设备
- 显示器
- 字符显示
- 图形显示(主观画图)
- 图像显示
- 打印机
- 显示器
- 其他
- 多媒体技术
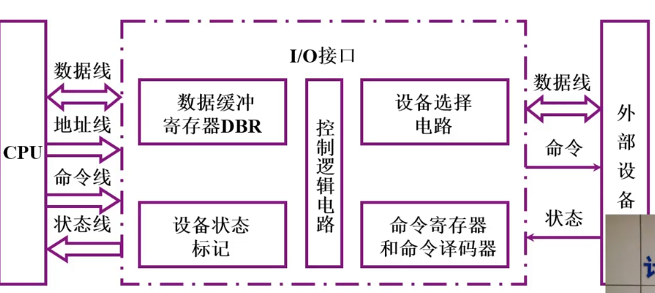
I/O接口
概述
接口功能和组成
1.总线连接方式的I/O接口电路
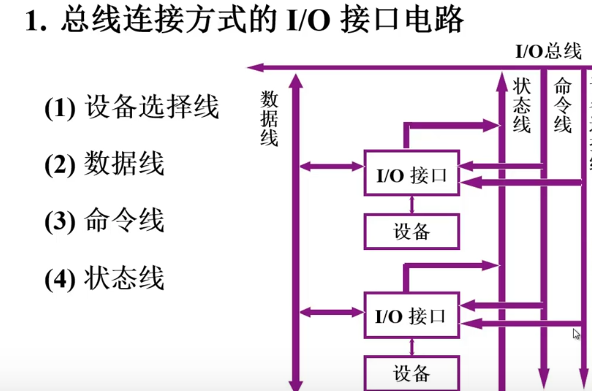
2.接口的功能和组成
|功能|组成|
|—-|—-|
|选址功能|设备选择电路|
|传送命令功能|命令寄存器、命令译码器|
|传送数据功能|数据缓冲寄存器|
|反映设备状态功能|设备状态标记|3.I/O基本接口组成
接口类型
接口分类
1.按数据传送方式
- 并行接口
- 串行串行
2.按功能选择的灵活性分类
- 可编程接口
- 不可编程接口
3.按照通用性分类
- 通用接口
- 专用接口
4.按照数据传送的控制方式分类
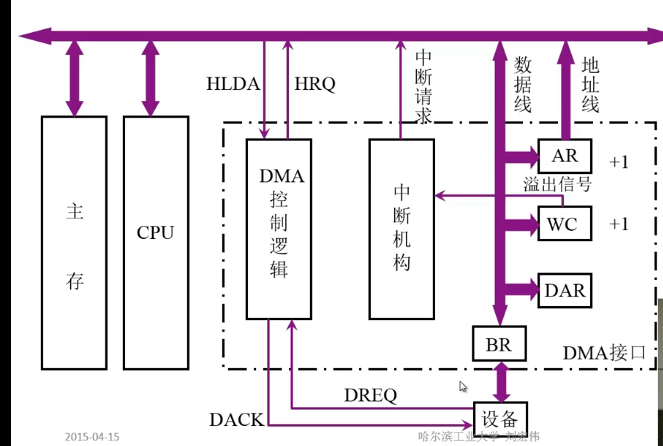
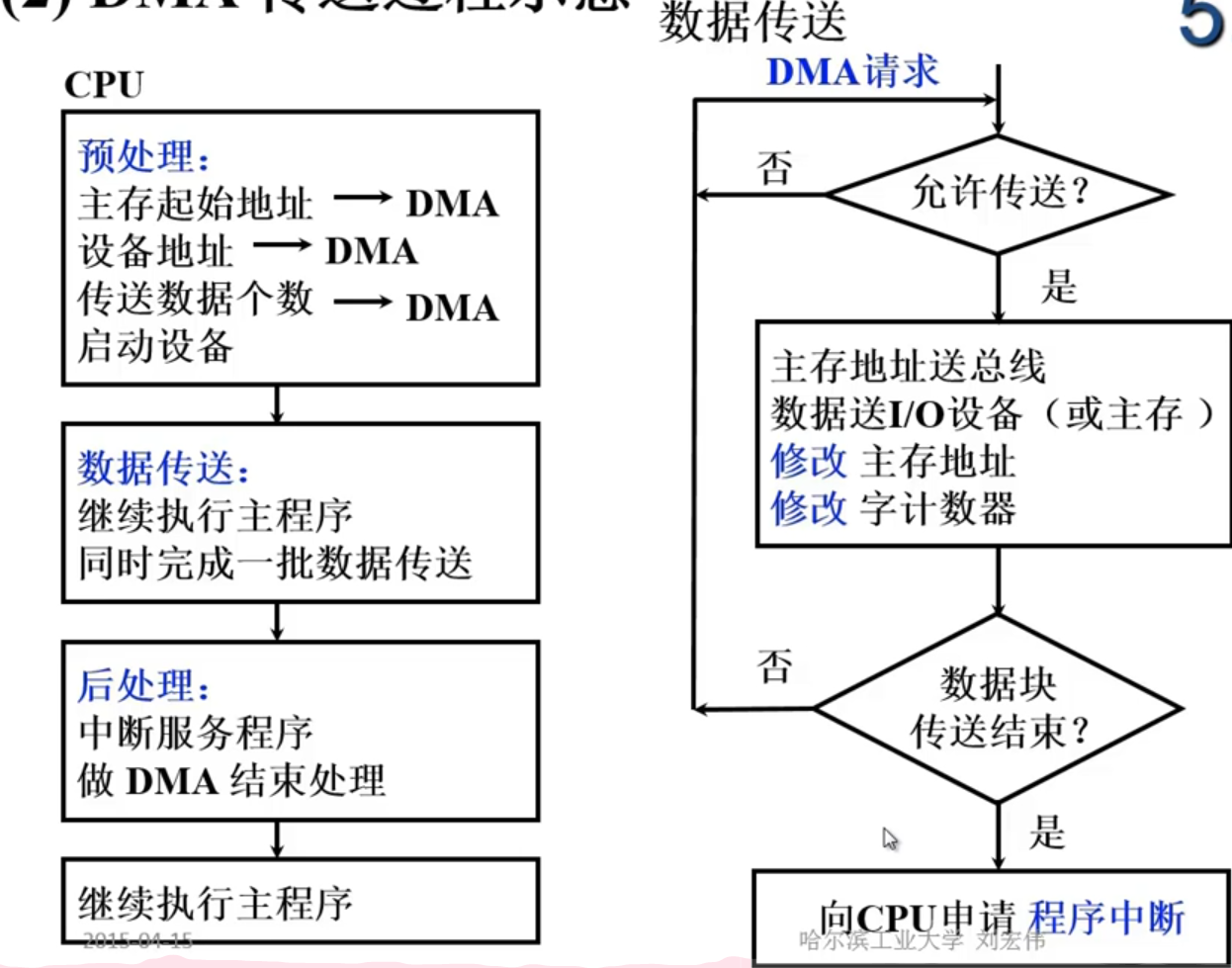
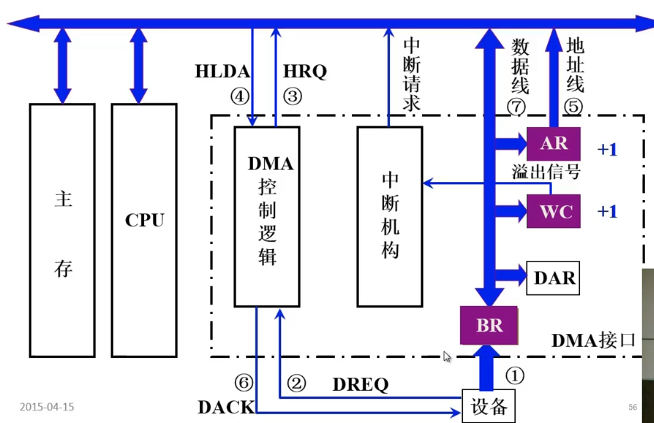
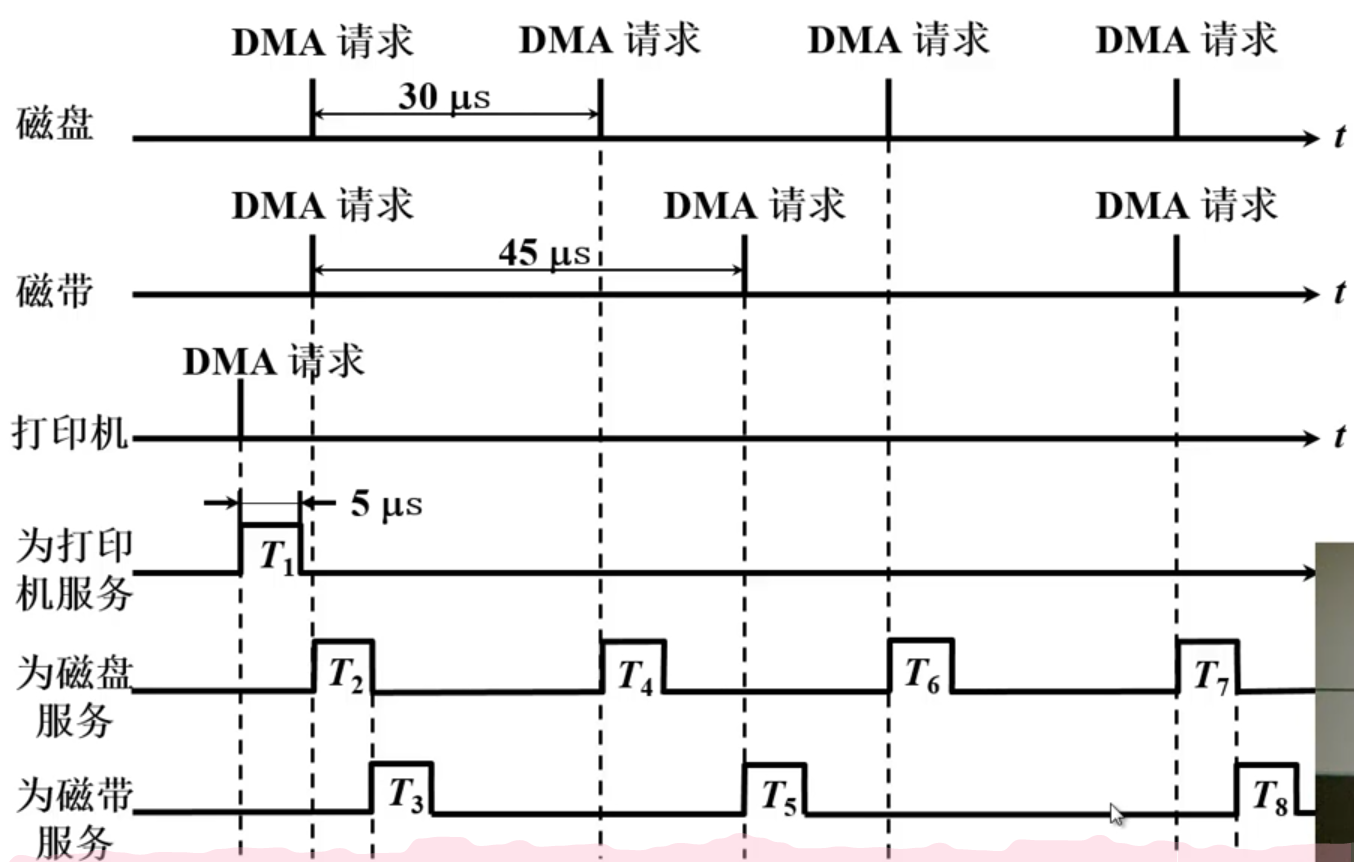
- 中断方式
- DMA方式
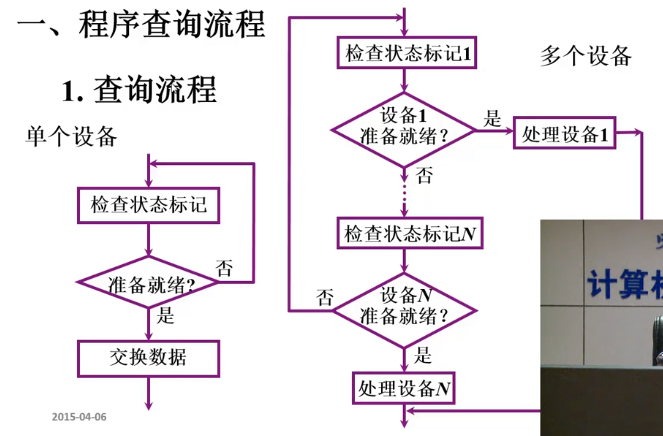
程序查询方式
1.程序查询流程
查询流程
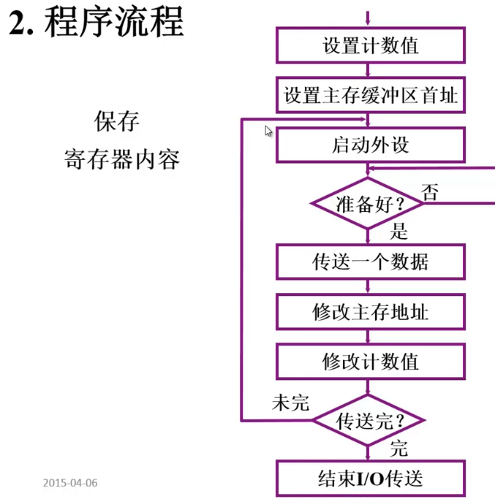
2.程序流程
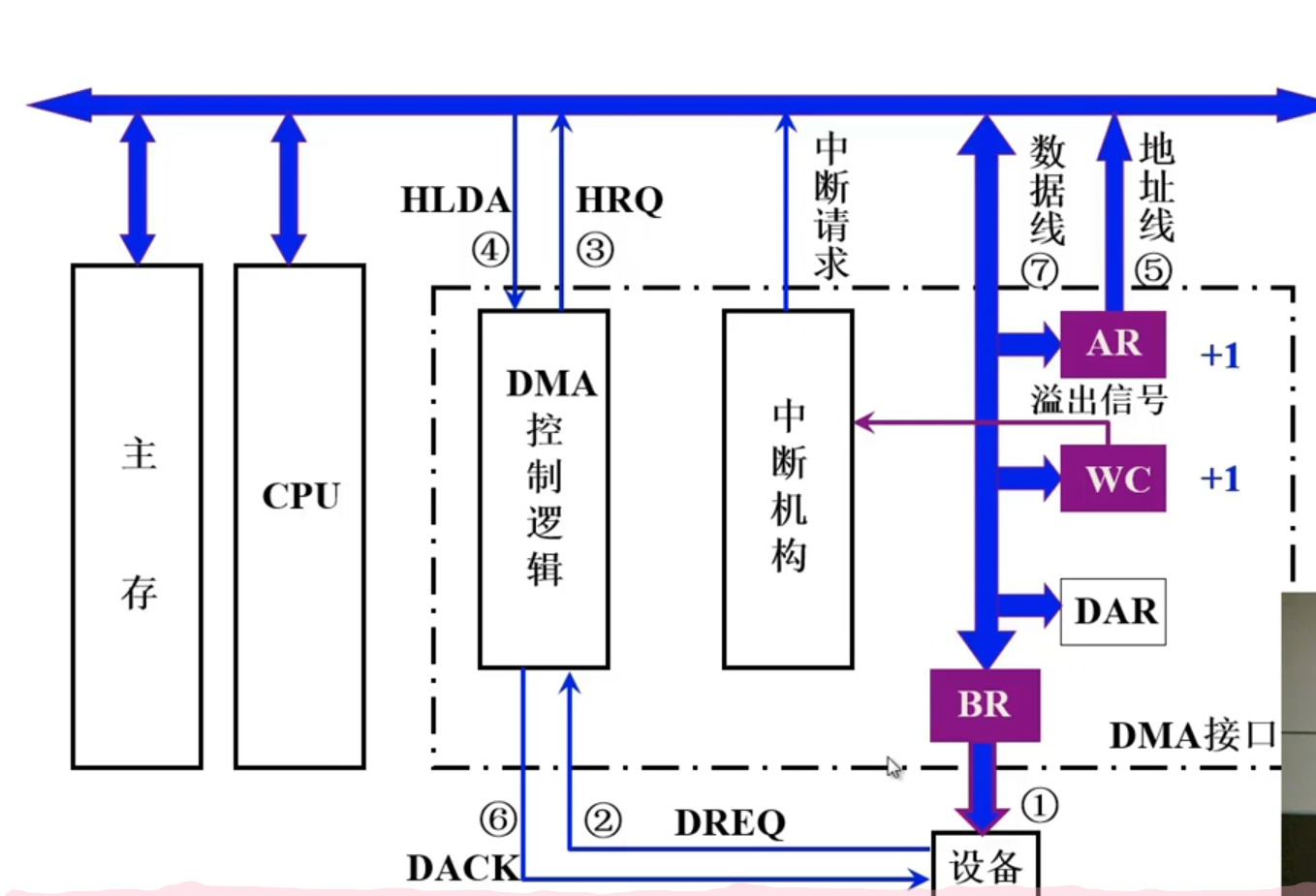
程序中断方式
概念
CPU在执行程序过程中,如果发生意外事件或者特殊事件,CPU要中断当前事件去处理特殊事件。通过执行中断服务程序的方式去处理特殊事件,处理结束后返回被中断程序的程序断点。I/O中断的产生
程序中断方式的接口电路
- 配置中断请求触发器和中断请求屏蔽器
- 排队器
- 中断向量地址形成部分